최근 랩실에서 에어로젤과 관련된 실험을 하고 있습니다. 이때, 온도와 압력이 중요한데, 사용하는 압력계는 디지털이 아니라 아날로그라 시간에 따른 압력을 추적하기가 어려웠습니다. 그래서 인터넷에서 조사를 하던 중, 라즈베리 파이와 OpenCV 라이브러리를 이용하면 아날로그 게이지를 읽을 수 있는 프로그램을 만들 수 있다고 하여, 관련 자료를 아래 글에 정리하기 시작하였습니다.
1. Introduction
1.1 문제상황
현재 제가 디지털화를 해야하는 것들은 두 가지입니다; 온도계와 압력계. 온도계의 경우 소수점 한자리를 포함한 4자리 디지털숫자로 표기가 되고 압력계의 경우 원형 아날로그 게이지입니다. 따라서, 현재의 목표는 라즈베리파리와 연결된 카메라를 이용하여 두 물리량을 하나의 사진에 캡쳐를 합니다. 그 후 그 사진을 기반으로 OpenCV를 이용하여 우리가 원하는 물리량을 읽는 것입니다.
대략적으로 라즈베리파이에서 찍은 사진에서 LDC 패널과 압력 게이지는 아래의 사진과 같습니다. 참고로 라즈베리파이에 연결된 카메라는 5MP 화소에 대략적으로 1미터 정도 fume hood에서 떨어져 있습니다.

이때, 라즈베리파이로 찍은 사진들을 비교했을 때, 같은 인덱스로 이미지를 자르는 경우에도 원형 게이지나 LCD
1.2. 워크 플로우
워크 플로우는 간단합니다.
• 라즈베리 파이에 연결된 카메라가 지정된 시간에 사진을 찍음
• 파이썬으로 작성된 코드로 OpenCV를 활용하여 사진을 적절히 이미지 처리 후, (1) LCD 패널의 숫자와 (2) 압력 게이지의 눈금을 읽음
• 얻어진 데이터들을 구글 스프레드시트에 업로드
1.3. OpenCV
이번 개인적인 프로젝트에서는 이미지 처리가 핵심이기 때문에, opencv는 필수적입니다. 그러면 opencv란 무엇일까요? OpenCV란 Open Computer Vision의 약자로 이미지 프로세싱 분야의 다양한 프로젝트에서 사용되고 있는 강력한 라이브러리 중 하나입니다. 이러한 OpenCV를 사용하기 위해선, 먼저 (1) 라즈베리 파이에 Linux기반 OS가 설치되어야 하며, (즉, 일반적으로 Raspbian이 이미 라즈베리파이에 기본적인 OS로 설치가 되어있을 것입니다.) (2) 카메라가 라즈베리 파이에 연결이 되어야 하고, (3) OpenCV가 설치되어야 합니다
1.3.1. 라즈베리 파이에서 카메라 설정
$ sudo raspi-config: 터미널에서 해당 명령어를 입력 후, `Interface Options` > `Legacy Camera` > `YES`를 선택하여 카메라 모듈이 가능하도록 설정한 후 재부팅한다. *
* 라즈베리 4의 경우, 별도의 설치 없이 `libcamera` 명령어를 사용할 수 있다.
** 만약 해당 명령어가 적용되지 않을 경우, 다음 명령어로 카메라가 감지되는지 그리고 감지된 카메라로 사진을 찍을 수 있는지를 확인한다.
- 라즈베리와 연결된 카메라 확인: `libcamera-still --list-cameras`
- 카메라로 사진 찍기: `libcamera-jpeg -o test.jpg`
1.3.2. OpenCV 설치
▪ OpenCV 설치를 위해 아래의 명령어를 입력한다.
1) `$ pip3 install opencv-python`
2. 원형 게이지 읽기
다음으로, 원형 압력 게이지를 이미지 처리를 통해 읽는 방법에 대해서 다루도록 하겠습니다. 아래는 코드를 작성할 때, 참고한 Reference들입니다.
Reference
[1] https://stackoverflow.com/questions/46513323/how-to-read-utility-meter-needle-with-opencv
[2] https://sdsawtelle.github.io/blog/output/automated-gauge-readout-with-opencv.html
[3] https://www.weigu.lu/other_projects/python_coding/read_analogue_gauge/index.html
[4] https://github.com/intel-iot-devkit/python-cv-samples/blob/master/examples/analog-gauge-reader/analog_gauge_reader.py
원형 아날로그 게이지를 읽기 위해 제가 작성한 프로그램의 워크플로우는 다음과 같습니다.
(1) 원본 이미지에서 대략적으로 원형 게이지가 나오는 부분을 잘라냄
(2) OpenCV 내의 Hough 알고리즘인 `cv2.HoughCircles`을 사용하여 원형게이지의 바깥족 원형 가장자리 및 이 원의 중심과 반지름을 찾아냄
(3) 해당 원의 중심에서 대략 `0.5*r` 만큼의 픽셀만큼 잘라냄
(4) 게이지의 needle을 찾는 알고리즘을 실행
위의 출처에 따르면, 크게 원형 아날로그 게이지의 눈금을 읽는 방법은 크게 2가지가 있습니다.
방법 a) 적절한 이미지 프로세싱을 통해, OpenCV 내의 Hough 알고리즘을 사용하여 (즉, `cv2.HoughLinesP()`) 바늘의 위치를 찾아냄 [3][4].
방법 b) 출처 [2]의 방법
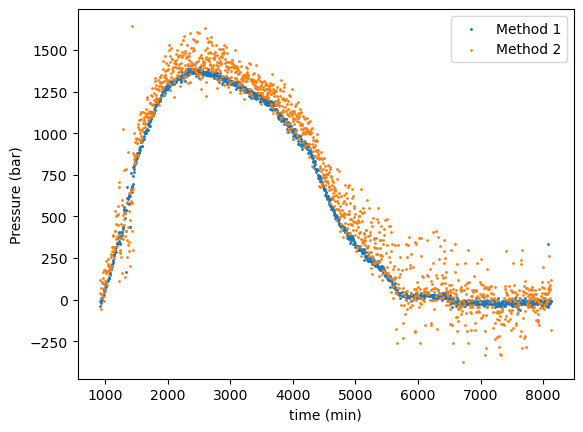
아래는 두 방법을 모두 사용하여, Figure 2에서는 제가 카메라로부터 얻은 약 1000 장의 이미지를 이용하여 아날로그 게이지를 읽은 값들을 보여주고 있습니다. 방법 a)의 경우, 방법 b)에 비해 에러가 많다는 것을 볼 수 있습니다. 몇가지 이유가 있을 수 있겠지만, 첫번째로, 이미지의 해상도가 크게 좋지 않으며, 게이지의 바늘의 두께가 일정하진 않습니다 (바늘의 두께가 일정하지 않아 여러 선들이 같이 얻어짐). 또한, 가장 중요하게도, 방법 a)의 경우, Hough 알고리즘으로 needle의 위치를 정확히 찾는 건 이미지 처리를 어떻게 하느냐에 따라에 많이 의존합니다. 따라서, 비전문가인 제 입장에서는, 시간 투자 대비, 방법 a) 보다는 방법 b)가 더 정확하고 간단하였습니다.
따라서, 여기에서는 출처 [2]에 나온 방법을 제가 살짝 수정한 버전으로 설명하고자 합니다.
2.1. 원형 게이지 읽기
우선, 원본 이미지에서, 원형게이지가 보이는 부분만 아래 Figure 3과 같이 선택합니다.

매 5분마다 라즈베리파이에 설치된 카메라를 이용히여 사진을 찍고 원본사진들로부터 동일한 인덱스로 원본 사진을 다음과 같이 잘라 냈을 때, (예: `imag[10:100][20:200]` (imag는 openCV로 불러온 원본 이미지)), 게이지가 조금씩 움직이는 것을 확인했습니다. 따라서, 게이지가 움직이더라도 대략적으로 게이지의 위치를 매번 자동으로 찾기 위해서 Hough 알고리즘을 사용하여 원형 게이지의 둘레를 찾도록 하였습니다.
원형 게이지의 경계를 찾는 것: OpenCV는 이미지에서 원을 찾을 때, "Hough Circle Transform"이라는 것을 사용합니다[1]. 알고리즘에 대한 자세한 설명은 [1]을 참조하시길 바랍니다. 일반적으로 경계를 찾기 위해선 다음과 같은 단계를 거칩니다.
(1) 이미지를 `cv2` 모듈의 `imread`를 이용하여 불러오기
- `cv2.imread()`: https://docs.opencv.org/3.4/d4/da8/group__imgcodecs.html#
(2) 해당 이미지를 `cv2` 모듈의 `cvtColor`를 사용하여 회색으로 변환
(3) 변환된 이미지에서 `HoughCircles`을 사용하여 원들의 x,y 좌표와 반지름을 찾기
- 이 단계에서는 파라미터들을 조절하면서 최적화된 파라미터들을 찾아야 한다.
- `HoughCircles`: https://docs.opencv.org/3.4/dd/d1a/group__imgproc__feature.html#
NOTE: `HoughCircles`의 매개변수들: `HoughCircles(image, method, dp, minDist, circles, param1, param2, minRadius, maxRadius)`
▪ `image`: `HoughCirlces()` 에 입력되는 이미지 (단, 그레이스케일이여야 함)
▪ `method`: 현재 opencv에서 사용할 수 있는 방법은 `cv2.Hough_GRADIENT`만 가능
▪ `dp`: 감지하는 원의 중심위치의 해상도를 조절하는 매개 변수
- `dp=1`이면 입력 이미지와 동일한 해상도로 원을 감지, `dp=2`이면 해상도가 절반으로 감소
▪ `minDist`: 감지된 원들의 최소 거리
- 해당 값을 너무 작게 설정할 경우, 여러 원들이 중복될 수 있음
- 해당 값이 너무 클 경우, 일부 원이 감지되지 않을 수 있음
▪ `circles`:
▪ `param1`: 엣지검출에서 사용하는 Canny 엣지 검출기의 임계값
▪ `param2`: 중심과 반지름을 결정하는데 사용하는 임계값
- 값이 작을수록 더 많은 원들이 감지
▪ `minRadius`: 감지할 원의 최소 반지름
▪ `maxRadius`: 감지할 원의 최대 반지름
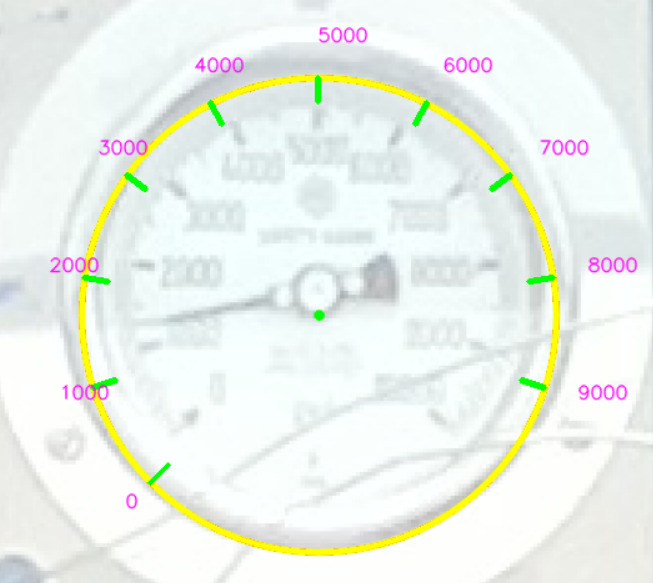
Hough 알고리즘으로 우리가 원하는 원을 찾기 위해선, 어쩔 수 없이, Trial & Error로 여러 번 시도하면서, 적절한 파라미터를 찾아야 합니다. 만약 적절한 파라미터를 찾은 후, 대략적인 눈금의 위치들을 표시를 하면 아래와 같습니다. 아래 Figure 4를 보면 알다싶이, 검출한 원의 중심이 게이지의 중심에 있지 않습니다. 하지만 검출한 원이 정확하게 게이지의 중심에 위치하지 않지만, 검출한 원의 중심이 게이지의 중심의 근청에 있다는 점을 이용하여 이후, 바늘의 위치를 찾을 예정입니다.
아래는 제가 작성한 코드의 일부입니다.
######################################################################################
# Global variables used in Pressure gauge
######################################################################################
rotation_angle_in_gauge = 270 # unit:degree
min_value = 0 # unit:psi
max_value = 10000 # unit: psi
n_main_ticks = 10 # the number of main ticks
start_angle = 135
separation = rotation_angle_in_gauge/n_main_ticks # The interval angles between main ticks in degree
interval_value = (max_value-min_value)/n_main_ticks
DegToRad = np.pi / 180
def Detect_Pressure_Gauge(imag, show=False, save = False, name = "default"):
'''
1. Purpose of the function:
From the cropped image, this function will detect the circumference of the pressure gague, using Hough algorithm.
As a result, it returns its center position in xy coordinates as well as its radius.
2. Input parameters
(1) imag: the cropped image where the pressure gauge is
(2) show: If it is True, then it shows detected circle and its center
(3) save: If it is True, the image containing detected circle and its center will be saved
3. Output parameters: center position (x,y) and the radius (r) of the detected pressure gauge
'''
height, width = imag.shape[:2] # Get the hieght and width of the image in the unit of pixel
gray = cv2.cvtColor(imag, cv2.COLOR_BGR2GRAY) # Convert the image to gray scale
#thresh = cv2.threshold(gray, 20, 255, cv2.THRESH_BINARY_INV)[1]
#################### Detect circles ################################################
MinRatio = 0.375 # The minimum radius of the circle in the entire pixel
MaxRatio = 0.380 # The maximum radius of the circle in the entire pixel
# Note that the output of a function "HoughCirlce" is as follows;
# [[ ... ,[x_i,y_i,r_i], ... ]]
# x_i: x componennt of the center for i-th circle
# y_i: y componennt of the center for i-th circle
# r_i: radius for i-th circle
circle_list = cv2.HoughCircles(gray, # Image
cv2.HOUGH_GRADIENT, # Method
2, # dp
400, # minDist
np.array([]), #
40, # param1
30, # param2
int(height* MinRatio), # minRadius
int(height* MaxRatio)) # maxRadius
circle_list = np.uint16(np.around(circle_list))
x, y, r = avg_circles(circle_list) # Extract the average coordinate for center and its radius
if show == True:
for circle in circle_list[0, :]:
x1,y1,r1 = circle
cv2.circle(imag, (x1,y1), 1, (0, 100, 100), 3)
cv2.circle(imag, (x1,y1), r1, (0, 0, 255), 3)
cv2.circle(imag, (x, y), r, (0, 255, 255), 3, cv2.LINE_AA) # draw circle
cv2.circle(imag, (x, y), 2, (0, 255, 0), 3, cv2.LINE_AA) # draw center of circle
# define lists where the information about points will be stored
p1 = np.zeros((n_main_ticks,2)) #set empty arrays
p2 = np.zeros((n_main_ticks,2))
p_text = np.zeros((n_main_ticks,2))
for i in range(0, n_main_ticks):
for j in range(0,2):
angle = ( separation * i - start_angle ) * DegToRad
center = np.array([x,y])
tick_pos = r * np.array([np.cos(angle), np.sin(angle)])
p1[i] = center + tick_pos * 0.9
p2[i] = center + tick_pos * 1.0
p_text[i] = center + tick_pos * 1.15
for i in range(0,n_main_ticks):
cv2.line(imag, (int(p1[i][0]), int(p1[i][1])), (int(p2[i][0]), int(p2[i][1])),(0, 255, 0), 3)
cv2.putText(imag, '%s' %(int(i*interval_value)), (int(p_text[i][0]), int(p_text[i][1])),
cv2.FONT_HERSHEY_SIMPLEX, 0.5,(255,0,255),1,cv2.LINE_AA)
cv2.imshow("imag", imag)
cv2.waitKey(0)
return x,y,r3.2. 눈금 읽기

[1] https://docs.opencv.org/3.4/d4/d70/tutorial_hough_circle.html
[2] https://docs.opencv.org/3.4/d9/db0/tutorial_hough_lines.html
[3] https://www.weigu.lu/other_projects/python_coding/read_analogue_gauge/index.html
[4] https://docs.opencv.org/3.4/d9/db0/tutorial_hough_lines.html
3. LCD 디지털 숫자 읽기
다음으로 하는 작업은 LCD Display 위에 있는 Digits을 OpenCV를 통해 읽는 것입니다. 현재 랩실에서 사용하는 건 숫자가 "Seven-Segment display"로 표기됩니다. 이 때, LCD 패널에 있는 숫자를 인식하기 위해선 크게 세가지 방법이 있습니다.
1) 머신 러닝 혹은 딥러닝을 이용
(a) Tesseract ocr을 이용
(b) TensorFlow나 CNN등 딥러닝 기술을 이용하는 것
2)
우리는 1)-(a)와 2) 방법에 대해서 다룰 예정입니다. 이후에 시간이 나면, TensorFlow나 CNN을 이용한 방법도 정리를 해볼까 생각합니다. 이러한 딥러닝 방법에 대해서 관심이 있는 분들은 아래의 레퍼런스들을 참고하면 좋을 것 같습니다.
• A. Wannachai, et.al, Real-Time Seven Segment Display Detection and Recgnition Online System Using CNN
• T. S. Gunawan, et.al, Development of Seven Segment Display Recgnition Using TensorFlow on Raspberry Pi
먼저, 기본적인 순서들은 아래와 같습니다.
Step 1:
OpenCV와 연계한 작업은 다음 웹사이트에 잘 설명이 되어있다.
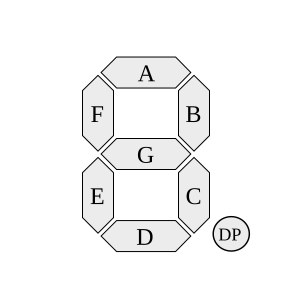
NOTE: Seven-Segment Display란? Seven-Segment Display는 7개의 선분이 On/Off를 함으로써, 기본적으로 총 128개의 상태들을 표시할 수 있다. 하지만, 우리가 관심있는 것은 정수 0~9까지 총 10개의 상태만 관심이 있다. 따라서, 우리가 할 일은 OpenCV를 통해 이 10가지 상태를 얻는 것이다.
NOTE: `cv2.Canny(image, lowthreashold, maxthreshold, apertureSize, L2gradient) `
※ 필수 URL
- https://www.geeksforgeeks.org/python-opencv-canny-function/
- https://docs.opencv.org/4.x/da/d22/tutorial_py_canny.html
1) `lowthreshold`:
- min value보다 작은 intensity gradient를 가지는 필셀들은 Edge가 아니라고 가정되며 버려짐
2) `maxthreshold`:
- maxthreshold (혹은 max value)보다 큰 intensity gradient를 가지는 픽셀들은 Edge로 고려됨
- 만일 max value와 min value 사이의 값을 가지는 픽셀의 경우, connectivity에 따라 classified edge 혹은 non-edge로 결정
3) `apertureSize`: Canny 알고리즘 내의 Gradient를 계산하기 위해 사용되는 Sobel filter의 order를 결정
- 3,5,7 중 하나만 선택할 수 있으며, 숫자가 커질수록 더 자세한 디테일들을 검출
4) `L2Gradient`: L2Gradient 알고리즘에서 사용하는 Gradient의 식
- 식은 단순히 $L2 = \sqrt{G_x^2 + G_y^2}$
- L1의 경우, $L1 = abs(G_x) + abs(G_y) $
3.2.2. 숫자 인식하기
3.2.2.1. Tesseract OCR 이용하는 방법
숫자를 인식하기 위한 가장 쉬운 방법 중 하나는 누군가 트레이닝 시켜놓은 머신러닝 데이터를 이용하는 것입니다. Tesseract는 2006년도부터 구글에서 개발한 광학 문자 인식 엔진입니다. 이 소프트웨어를 python에서 사용하기 위해선 해당 필요 프로그램들을 다운 및 설치를 해야합니다.
■ 설치할 프로그램들
(1) `pytesseract` 설치: `pip install pytesseract`
(2) `tesseract` 설치
- 설치 url: https://github.com/UB-Mannheim/tesseract/wiki
- 위 링크에서 tesseract-ocr 설치 파일을 받은 뒤 설치한다. 그 후, `시스템 환경변수 편집`에서 PATH에 tesseract가 설치한 폴더 주소를 기입합니다.
하지만, 일반적으로 tessearct ocr은 Seven-segment display(SSD)를 잘 인식하지 못합니다. 그래서, SSD digit을 인식하기 위해서, 이미 다른 사람들이 머신러닝으로 훈련을 시켜놓은 소스들을 다운받아 사용해야 합니다. 해당 파일들은 아래의 링크들에 있습니다.
■ Tesseract SSD 학습데이터와 연관된 링크들
(1) https://github.com/arturaugusto/display_ocr
- 대략 10년전에 트레이닝된 SSD digit 데이터들
- 위 깃헙에서 letsgodigital 내에 있는 모든 파일들을 다운받는다. 그 파일들을 tesseract의 설치 폴더 내의 tressdata 폴더에 이동시킨다.
- 0을 제외한 나머지 숫자들은 잘 인식하는 편이다. 하지만, 0은 9 혹은 8로 인식이 되는 경우가 있다.
(2) https://github.com/upupnaway/digital-display-character-rec/
- 위와 동일한 문제점을 가지고 있음. 아마 동일한 trained data인 것 같음
(3) https://github.com/adrianlazaro8/Tesseract_sevenSegmentsLetsGoDigital
- 개인적으로 사용했을 때, 괜찮은 결과물을 제공했음. (1)과 마찬가지로 위 깃헙에서 Trained data 폴더 내의 파일들을 모두 다운 받은 후, tressdata로 이동시킨다.
(4) https://github.com/Shreeshrii/tessdata_ssd?tab=readme-ov-file
- 아직 사용해보진 않음
저는 위 링크 중 (3)을 선택해서 진행하였습니다. 그 후, 숫자를 인식하는 것은 생각보다 간단합니다. 아래 코드를 입력하면 위에서 얻은 SSD 숫자인 2055를 얻을 수 있습니다.
>>> import pytesseract
>>> pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
>>> digits = warped[20:-100, 60:]
>>> temp = pytesseract.image_to_string(digits, lang="lets", config= "--psm 6 -c tessedit_char_whitelist=.0123456789")
>>> print(temp)
2055• 2 번째 줄: 간혹, Tesseract orc를 설치하고 두번째 줄을 입력해야지 python 내에서 tesseract 실행 파일을 찾을 수 있습니다.
• 4 번째 줄: tesseract orc를 통해서, 주어진 학습 데이터 (`lets`)를 이용하여 digits을 추출하는 과정
3.2.2.3. TensorFlow lite과 CNN 알고리즘 및 MNIST를 활용하여 숫자 인식
1) 라즈베리파이에서 TensorFlow lite 설치하기
※ TensorFlow Lite란? 라즈베리 파이와 같이 저전력 기기에서 사용하도록 디자인된 TensorFlow의 가벼운 버젼
- TensorFlow Lite에선, 특정 모델을 트레이닝하기 위해선 사용할 수 없으며, 이미 트레이닝이 된 모델들을 TensorFlow Lite에서 사용할 수 있음
라즈베리 파이에서 TensorFlow Lite를 설치하기 위해서, 우선, 아래의 명령어를 입력한다.
※ 라즈베리파이에 TensorFlow Lite를 어떻게 설치하는지는 다음 웹페이지에 요약을 하였다. https://m31phy.tistory.com/844
2)
import os
from tflite_runtime.interpreter import Interpreter
TF_LITE_MODEL = './mnist.tflite' # TF lite model
# Load the TensorFlow Lite model
interpreter = Interpreter(model_path = TF_LITE_MODEL)
# Prepare the model
interpreter.allocate_tensors()
# Get the model's detail
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# get input shape
INPUT_H, INPUT_W = input_details[0]['shape'][1:3]
# floating_model = (input_details[0]['dtype'] == np.float32)
roi = cv2.resize(roi, (28,28))
input_data = np.expand_dims(roi, axis=0)
input_data = input_data.reshape(1, 28, 28, 1)
# Make prediction
interpreter.set_tensor(input_details[0]['index'], input_date)
interpreter.invoke()
predicted = interpreter.get_tensor(output_details[0]['index'])[0] # Confidence of detected objects
output_details = interpreter.get_output_details()
output_data = interpreter.get_tensor(output_details[0]['index'])
# get label and probability
label = predicted.argmax(axis=0)
prob = predicted[label]
for i in range(len(scores)):
if ((predicted[i] > min_conf_threshold) and (scores[i] <= 1.0)):
object_name = labels[np.argmax(output_data)] # Look up object name from "labels" array using class index
label = '%s: %d%%' % (object_name, int(scores[i]*100)) # Example: '7: 60%'
NOTE: 참조 Reference
[1] https://github.com/vkdnjznd/raspberry-mnist/
[2] https://github.com/alankrantas/MNIST-Live-Detection-TFLite/blob/main/mnist_tflite_detection.py
Appendix:
TF_LITE_MODEL = './mnist.tflite' # the file name for the generated TF Lite model
SAVE_KERAS_MODEL = True # save the original Keras model
import autokeras as ak
import tensorflow as tf
from tensorflow.keras.datasets import mnist
# load MNIST dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# train a AutoKeras model
clf = ak.ImageClassifier(max_trials=1, overwrite=True)
clf.fit(x_train, y_train)
# evaluate model
loss, accuracy = clf.evaluate(x_test, y_test)
print(f'\nPrediction loss: {loss:.3f}, accuracy: {accuracy*100:.3f}%\n')
# export model
model = clf.export_model()
model.summary()
# save Keras model if needed
if SAVE_KERAS_MODEL:
model.save('./mnist_model')
# convert to TF Lite model
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# converter = tf.lite.TFLiteConverter.from_saved_model('./mnist_model')
tflite_model = converter.convert()
# save TF Lite model
with open(TF_LITE_MODEL, 'wb') as f:
f.write(tflite_model)NOTE: 참조 Reference
[1]https://keras.io/examples/vision/mnist_convnet/
[2]https://github.com/alankrantas/MNIST-Live-Detection-TFLite/blob/main/mnist_tflite_detection.py
[3] https://ultrakid.tistory.com/?page=3
[1] https://github.com/intel-iot-devkit/python-cv-samples/tree/master/examples/analog-gauge-reader
https://www.geeksforgeeks.org/blob-detection-using-opencv/
https://en.wikipedia.org/wiki/Blob_detection
https://hackmd.io/@lKuOpplzSUWLhLim2Z7ZJw/SkL-qU2Wh
'컴퓨터 & IT (Computer & IT) > Raspberry pi 3' 카테고리의 다른 글
| [라즈베리파이] VNC-cannot currently show the desktop (0) | 2025.02.07 |
|---|---|
| [라즈베리파이] 텐서플로우 라이트 설치 (0) | 2025.01.10 |
| [Rasberry pi] 라즈베리 파이를 이용한 서버실 온도 체크 (0) | 2021.07.28 |
| 라즈베리파이를 노트북과 내부망으로 연결하고 노트북 와이파이를 통해 인터넷 연결하는 방법 (12) | 2020.11.03 |


댓글